
I recently got a notice that the traffic on this site had reached 80% of the budgeted transfer for the month. This is not necessarily bad news — occasionally someone posts a link to Reddit and traffic spikes for a while. However, the stats page looked completely normal. HMM.
Fortunately, Apache (the webserver program) keeps a log of all accesses to the website. Looking through the file, it seems that several rather asocial individuals in Romania, China, and other places had picked up the “hobby” of running scripts to attack websites, in hopes of using them to send out spam. People Are No Damn Good, as my grandmother often points out.
Apache’s log files, however, are pretty big. The current access.log file is some 180MB. Clearly the solution here is to fight scripting with scripting.
Here are some of the relevant tools:
cat: short for “catalog.” This simply types out a file, either to the display (the default) or to another program. Cat will be used here to simply print out the whole access.log file.
grep: Grep finds lines of a file containing something. In this case, we’re interested in anyone accessing a file called xmlrpc.php. Grep will take the input from cat, and pass on only the lines containing this string.
cut: I learned about this one today. Cut can select out a particular section of lines, based on character count. While the later Awk step (see below) probably makes this unnecessary, I used Cut to select just characters 1-15 of each line of text. This stripped version is then passed along to…
sort: Does what it says. It takes in a text file and sorts it into alphanumeric order. This prepares the file to be processed by…
uniq: This takes in a sorted file and removes all duplicate lines. From here, the (greatly shortened) file is then passed to:
awk: Awk is a general-purpose string processor, with lots of features. I don’t yet know a lot about it, but I’m using it here to retain only the characters before the first whitespace — and then add a scripting command around that.
So, using all of the above in order, I came up with the one-liner:
cat access.log | grep xmlrpc.php | cut -c1-15 | sort | uniq -u | awk ‘{print ” sudo /sbin/iptables -A INPUT -s “$1” -j DROP “}’ > loserfile
This command prints out the webserver access log, finds any instances of attackers attempting to access xmlrpc.php, locates their IP addresses from the relevant line, and creates a command to instruct the firewall to ignore all traffic from those IPs. Once “loserfile” is set executable and then run, the new rules go into place.
As the graph below shows, the tactic seems to have worked.
Hasta la vista, fetchers.
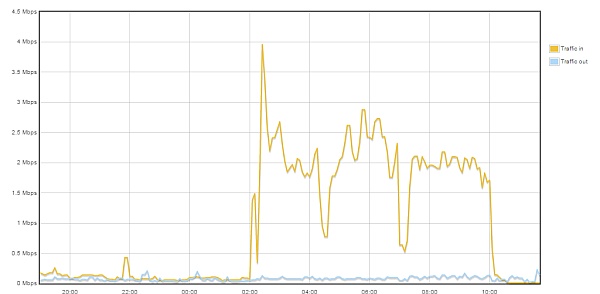
Hour-by-hour chart of inbound and outbound traffic
