Don’t look now, but that smartphone you’re carrying might be faster than your desktop. Even if not, modern smartphones are certainly capable enough to be used for many computing tasks traditionally left to desktops and laptops.
Smartphones typically have a single USB port — either MicroUSB or USB-C. For something like ten years now, these have generally all been capable of “USB On-The-Go” (USB-OTG) operations, where the smartphone switches functionality from USB device to USB controller. Plug in an inexpensive USB On-The-Go adapter, and your smartphone can access most of the same USB devices your desktop and laptop can. They can read and write flash drives, use USB keyboards and mice — and even program Arduino-compatible boards.
A Samsung A71 5G programming a TTGO T-Display via ArduinoDroid. This is the whole setup — no PC is needed (for simple sketches, anyway.) Even the Bluetooth keyboard is technically a luxury — if a very useful one!
I recently used a similar setup for troubleshooting a faulty speed sensor on a friend’s boat. A smartphone and Bluetooth keyboard are portable enough to use on board, where a laptop would be awkward and a desktop almost impossible to use.
I’ve started carrying a USB On-The-Go adapter with me. I figure if I’m already carrying the supercomputer, I might as well bring a USB port for it along.
When comparing the performance of computers across several generations (and often, several orders of magnitude in speed), it can sometimes be challenging to find an appropriate computational task that is scalable across a large enough range. Tasks that can take hours on a machine from the 1970s or 1980s (or earlier) can sometimes only take fractions of a second on a modern PC, skewing the results due to noncomputational overhead and quantization errors.
Fortunately, there exist several types of task that make at least limited speed comparisons possible. One such task for measuring integer-operation speed is the computation of the sums of the first 10^N prime numbers.
Prime numbers occur regularly enough to be a good benchmark, and sums of the first N primes are well-known, allowing verification of not only speed but algorithm correctness. This is a task that can both be accomplished by almost any computing device created — and yet can challenge even modern supercomputers. The task scales itself to the processor speed, even over many orders of magnitude.
The algorithm chosen is a simple not-quite-naïve for loop, checking each odd integer for divisibility by the odd numbers up to and including its square root. More sophisticated algorithms such as using the Sieve of Eratosthenes can speed up the calculation — but the idea is to use the simplest reasonable implementation possible, so it can be run on very simple machines. This way, the computing speed of vintage devices can be compared to modern ones — sometimes with fascinating conclusions. Machine-internal timing is used where possible.
Timex/Sinclair 1000 BASIC version. (Screenshot only for now; system still needs upload capability)
One interesting observation is that (for most setups where printing the data doesn’t take appreciable time) summing 10^(N+1) primes seems to always take about 33.3 times as long as summing only 10^N primes. This suggests a uniform way to scale the comparisons logarithmically, since each “level” (summing ten times as many primes) represents 33.3x as much computation. Scores for each machine under this scaling should be relatively consistent whether they’re calculating primes for a minute, an hour, or a week.
The Sinclair took about 175 seconds to calculate the sum of the first 100 primes, and 2526 seconds to compute the first 1,000. Assuming that each 10x increase in the number of primes computed represents a 33.3x increase in the number of computations, it’s reasonable to expect it to compute the sum of the first one million primes in about 175*(33.3^4) seconds (about 215.2 million seconds, or about 6.82 years.)
A good metric should be logarithmic for convenience. A reasonable one might be the log10 of the number of primes each machine would be expected to compute in 1000 seconds. With that, here are the results for various devices ranging from the 1980s to the present:
Timex/Sinclair 1000: 1,000 primes in 2,526 seconds: 2.74
TRS-80 Model 100: 10,000 primes in 3758 seconds: 3.62
ESP32: 10,000,000 primes in 24,629.97 seconds: 6.09
PocketChip: 1,000,000 primes in 460.38 seconds: 6.22
Northlight (Core i7/980X): 100,000,000 primes in 12,706.8 seconds: 7.27
Scientia (Core i9/9900): 100,000,000 primes in 9347.09 seconds: 7.36
Samsung A71 5G phone: 100,000,000 primes in 7099.7 seconds: 7.44
Note that these are logarithmic scales; each additional point means roughly a 10x speedup.
Some interesting observations:
The interpreted-BASIC machines are slowest, as was expected.
WinFBE’s compiler seems to be slightly better at integer ops than gcc.
Single-thread performance has not gotten significantly better in recent years.
If the slowest machine (the Sinclair) is compared to the speed of a literal snail, the fastest devices tested (desktops and a smartphone) would be about as fast as airliners. …but most surprisingly,
My Samsung A71 5G smartphone beat everything, including the desktops, and is something like 50,000 times as fast as the Timex/Sinclair, at computing primes. That’s not surprising — but I wouldn’t have guessed it would outrun a modern Core i9(!)
Finding the first ten primes in my head took me about twelve seconds as I was going to sleep. This would result in an equivalent score of about 2.26 (but wouldn’t scale very far.)
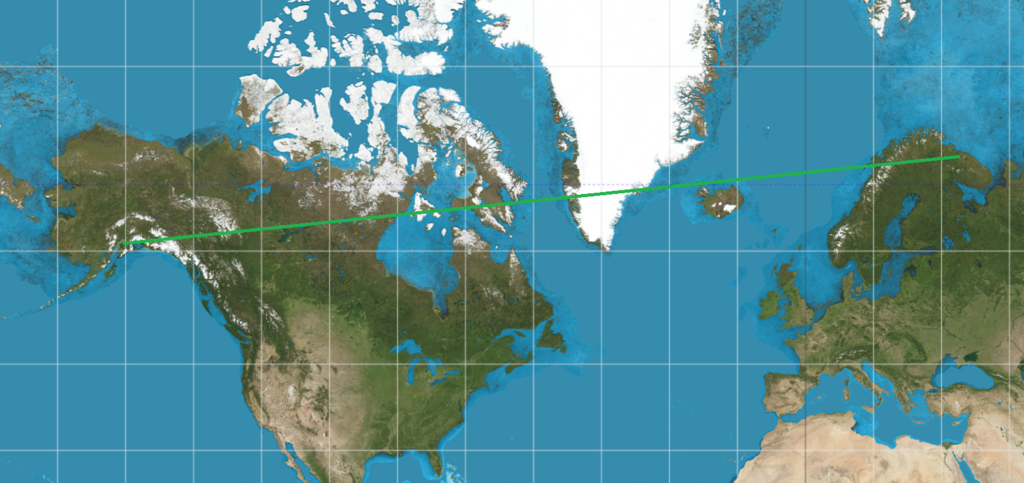
Although we’re all familiar with the flat Mercator map of the Earth, it exaggerates areas at high latitudes. More importantly for navigation, it also suggests very inefficient routing — routes calculated by taking the starting and ending latitude and longitude and using linear interpolation to find intermediate waypoints works well enough for low latitudes, but could end up suggesting a route that’s more than 50% longer, at high latitudes.
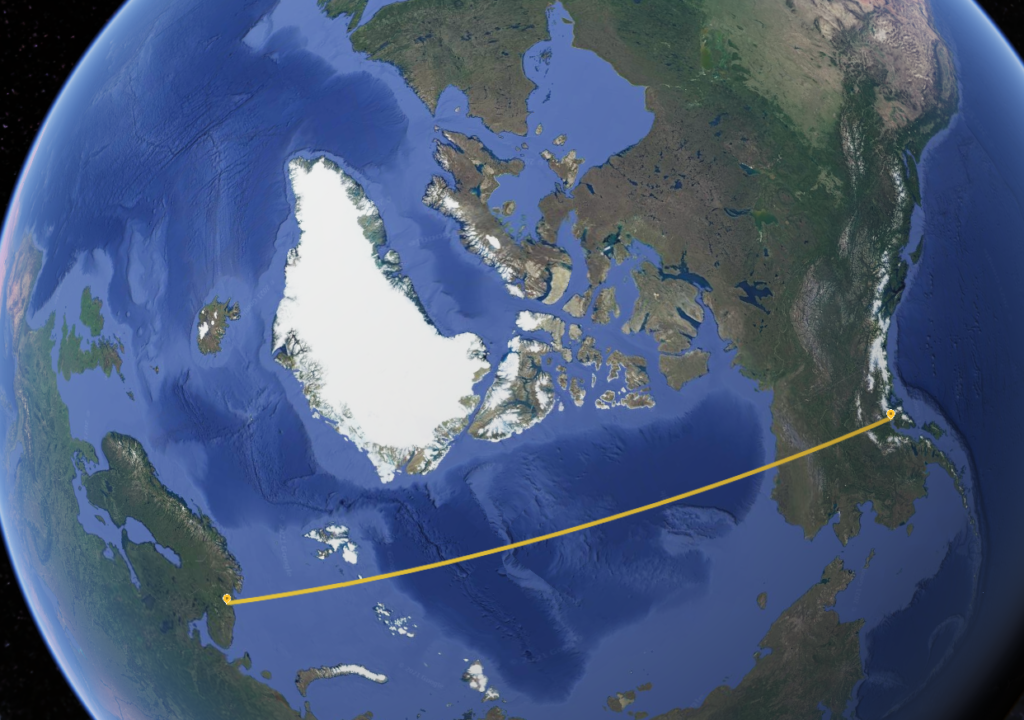
Consider a hypothetical flight from Murmansk (ULMM) to Anchorage (PANC). Although both cities are between 60 and 70 degrees north latitude, the shortest path between the two passes almost directly over the pole. In contrast, drawing a straight line between the two on a Mercator projection would imply a best path across Scandinavia, passing north of Iceland, then over Greenland and most of Canada before approaching Anchorage from the East.
It looks convincing, but the Flat Earth path will take a lot longer…The Great Circle route. Seen on a globe, this is the obvious shortest path.
So Great Circle routes are faster — but how can you calculate them? It seems complicated — but a key observation can help. The Great Circle route is the shortest route between two points along the Earth’s surface because it is the projection of the actual shortest path through space.
With this insight, we have a plan of attack:
Consider the Earth to be a unit sphere. This is slightly inaccurate, but it works well enough.
Convert the starting and ending points to XYZ Cartesian coordinates;
Choose how many points to interpolate along the route;
Interpolate these linearly (directly through XYZ-space — through the body of the Earth);
Extend the distance from the origin of each point so it sits on the unit sphere (I.E. compute the distance of the 3D point from the Earth’s core, and extend it to 1.0 length);
Compute the latitude of each point as arcsin(z), and the longitude as arg(x+yi).
While this method doesn’t split the path into equal length segments, it gets most of them fairly close, with segment distances varying by 20% or so. If desired, this could be adjusted by changing the points selected along the initial linear path.
Be careful when writing loops with unsigned variables. The compiler’s idea of an end condition might not match yours.
When working on a program to produce fractal laser-engraver art, I stumbled across a strange problem. I could call a function to draw a fractal at levels 0 through 6, all of which worked fine, whether individually or called in a for loop.
When I went to draw them in reverse order, however, the program crashed — and it didn’t make sense as to why. The code in question was something like:
dim as ulongint x for x=6 to 0 step -1 drawObject(x) next x
This worked fine forwards (for x=0 to 6) but crashed somewhere around level 2 when run in reverse — even though all levels worked great individually.
I eventually figured out that the bug was due to the variable in the for loop. Instead of iterating from 6 down to zero and then stopping, for loops (in FreeBasic as well as C) blindly decrement the variable and then check the end condition.
So, in C, a line which reads
for(uint8_t x=6;x>=0;x--){doTheThing(x);}
…will never return. It will get down to zero, decrement and wrap back to all-ones. Since this is a value greater than zero, it will continue.
In the case of the fractal image, I had unknowingly asked it to compute an 18.4667-quintillion-level Koch curve. This figure would have four-to-the-18.4667-quintillionth-power segments.